
《机器学习实战》--KNN算法
一、KNN算法的概念
KNN算法的定义很简单,就是找到一个和自己最相近的K个数据进行相比较提取K个数据中的相似数据最多的特征进行分类,作为新数据的分类。比如说现在有以下几个数据
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
| California Man | 3 | 104 | 爱情片 |
| He's Not Really into Dudes | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| 18 | 90 | ???? |
首先我们计算未知电影与样本集中的距离得到如下表格
| 电影名称 | 与未知电影的距离 |
| California Man | 20.5 |
| He's Not Really into Dudes | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
从表格中我们可以看出其余He’s Not Really into Dudes、Beautiful Woman、California Man三个电影的距离最短,故而我们可以判断其为爱情片。其实KNN和我们生活也很近,所谓近朱者赤,近墨者黑,与谁距离近就具备与其相似的特征。
二、实现过程
- 计算已知类别数据集中的点和当前点之间的距离
- 按照距离递增次序进行排序
- 选取与当前距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回k个点出现频率最该的类别作为当前点的预测分类。
距离:对于距离的定义有很多,比如说余弦距离,欧式距离等等,这里我们选用欧式距离。
三、具体代码
1.k-近邻算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(iteritems(classCount), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
前七行代码是用来据算距离的,起哄inX是用于分类的输入向量,dataSet是输入的样本训练集,labels为标签向量,k为选择最近的邻居数目。for循环是用来计算距离最小的k个点,倒数第二句是用来进行排序,最后返回频率最高的元素标签。
2.将文本转换为NumPy的解析程序
def file2matrix(filename):
fr = open(filename);
arrayOlines = fr.readlines();
numberOfLines = len(arrayOlines);
returnMat = zeros((numberOfLines, 3));
classLabelVector = [];
index = 0;
for line in arrayOlines:
line = line.strip()
listFromLine = line.split('\t');
returnMat[index, :] = listFromLine[0:3];
classLabelVector.append(int(listFromLine[-1]));
index += 1;
return returnMat, classLabelVector;
前五句是读取文件,得到文件的行数,然后创建返回NumPy的矩阵接着就是对读取文件的每一行去掉换行符和制表符然后进行分割成一个列表,最后返回
3.归一化特征值
def autoNorm(dataSet):
minVals = dataSet.min(0);
maxVals = dataSet.max(0);
ranges = maxVals - minVals;
normalDataSet = zeros(shape(dataSet));
m = dataSet.shape[0];
normalDataSet = dataSet - tile(minVals, (m, 1));
normalDataSet = normalDataSet / tile(ranges, (m, 1));
return normalDataSet, ranges, minVals;
采用newValue=(oldValue-min)/(max-min)进行数据的归一防止出现过大与过小的数据现象
4.测试算法
def datingClassTest():
hoRatio = 0.10 # hold out 10%
fig = plt.figure();
ax = fig.add_subplot(111);
datingDataMat, datingLabels = file2matrix('E:\Workspaces\eclipse\machinelearninginaction\Ch02\datingTestSet2.txt'); # load data setfrom file
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0 * array(datingLabels), 15.0 * array(datingLabels));
plt.show();
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount / float(numTestVecs)))
print (errorCount)
if __name__ == '__main__':
datingClassTest();
for循环之前的都是做数据的准备和归一在for循环中进行分类计算错误的比率。
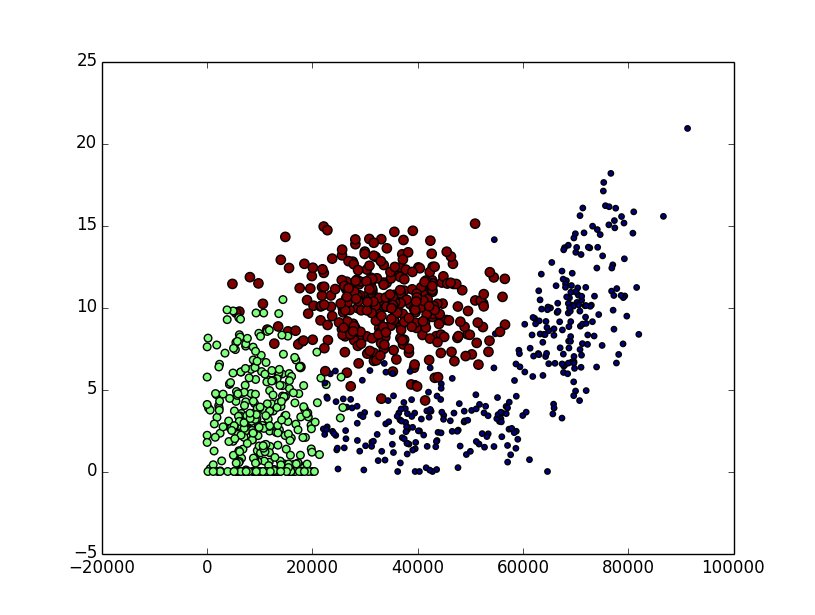
为了更好地看到数据的散点图可以用MatPlotLib创建一个散点图
代码如下:
'''
Created on 2014-3-18
@author: bearshng
'''
from numpy import *;
from charpter2 import kNN;
import matplotlib;
import matplotlib.pyplot as plt;
from ctypes import ARRAY
fig = plt.figure();
ax = fig.add_subplot(111);
datingDataMat, datingLabels = kNN.file2matrix('E:\Workspaces\eclipse\machinelearninginaction\Ch02\datingTestSet2.txt');
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0 * array(datingLabels), 15.0 * array(datingLabels));
plt.show();
结果图如下:
四、KNN的优缺点
优点:简单,真的很简单就是计算距离然后找出K个最近的距离
缺点:1.在计算的过程中需要计算距离和开放,计算量大。
2.如果数据量大,数据所需要的储存量也大。